




Spôsoby implementácie AI vo firmách, funkcie AI nad firemným know-how a s tým súvisiace aspekty zabezpečenia firemných dát

CEO, Kontis s.r.o.
45 minút čítania

Zhrnutie: Implementácia AI do firmy prináša nový pohľad na zabezpečenie firemných dát. Súčasné firemné bezpečnostné pravidlá pravdepodobne nebudú pokrývať situáciu po implementácii AI. Akými spôsobmi je možné AI do firmy implementovať, ako takto implementovaná AI funguje, na čo sa zamerať, aby firemné know-how bolo chránené dostatočne, implementácia AI bola efektívna a dávala zmysel, to všetko je predmetom tohto článku.
Executive summary
Implementácia umelej inteligencie (AI) na báze veľkých jazykových modelov (LLM) predstavuje zásadnú príležitosť, ako zvýšiť produktivitu zamestnancov, zefektívniť prácu s informáciami a lepšie využiť firemné know-how. Zároveň prináša nové riziká v oblasti zabezpečenia dát, kvality výstupov a riadenia prístupových práv. Tento článok približuje čitateľovi, ako vlastne AI na báze LLM funguje, opisuje tri základné metódy, ako AI vo firme implementovať a v závere uvádza ukážku konkrétnej implementácie AI.
Medzi 3 základné metódy implementácie AI nad firemným know-how patria:
1. Využívanie verejných AI nástrojov, napr. ChatGPT, Copilot
Rýchle a lacné riešenie bez nutnosti implementácie. Nie je však napojené na interné know-how firmy, čo obmedzuje jeho využiteľnosť. Pri práci s internými dátami vzniká riziko ich úniku mimo firmu.
2. Tréning vlastného AI modelu nad firemnými dátami
Technicky komplexný a finančne náročný prístup. Prináša vysokú mieru kontroly nad dátami, ale má zásadné nevýhody, najmä obtiažnu aktualizáciu znalostí, riziko nepresností a nemožnosť efektívne riadiť prístupové práva k informáciám vo vnútri firmy.
3. RAG (Retrieval-Augmented Generation) architektúra – odporúčaný prístup
Moderná a v súčasnosti najrozšírenejšia metóda. Kombinuje výhody oboch predchádzajúcich prístupov:
- AI pracuje s aktuálnym firemným know-how bez nutnosti tréningu modelu
- odpovede sú podložené konkrétnymi zdrojmi
- je možné efektívne riadiť prístupové práva k informáciám
- minimalizuje riziko halucinácií a nepresností
Z pohľadu väčšiny organizácií predstavuje RAG architektúra najlepší pomer medzi nákladmi, bezpečnosťou a kvalitou výstupov, viď porovnanie nižšie.
Kľúčové faktory úspechu implementácie
- rámcové pochopenie fungovania AI na báze LLM, podrobne v prvej kapitole
- porozumenie výhodám aj nevýhodám metód implementácií, podrobne v druhej kapitole
- kvalitne štruktúrované a spravované firemné know-how
- správne nastavené riadenie prístupových práv a zabezpečenie dát interne aj voči externým službám
- zapojenie zamestnancov a riadenie zmeny, tzv. change management
Odporúčania
Pre väčšinu firiem, ktoré chcú efektívne využívať AI nad vlastným know-how, je najvhodnejší prístup:
- implementácia AI na báze RAG architektúry
- využitie už hotovej platformy, ktorá minimalizuje náklady na vývoj a prevádzku. Praktická ukážka takejto implementácie na báze platformy iTutor je v poslednej kapitole.
Tento prístup umožňuje dosiahnuť rýchle výsledky pri zachovaní vysokej úrovne bezpečnosti a kvality výstupov.
Fungovanie AI na báze LLM nad firemným know-how
V článku sa zaoberáme implementáciami, kedy AI pracuje s firemným know-how a pomocou Chatbotov, Agentov a ďalších prostriedkov pomáha zamestnancom plniť efektívnejšie ich pracovné úlohy, či dokonca AI časť týchto úloh preberá a vykonáva ich sama.
Pre určenie, akú metódu takejto implementácie AI zvoliť a aké prijať nové pravidlá zabezpečenia dát, je dobré porozumieť konkrétnym metódam implementácie AI a rámcovo pochopiť fungovanie AI nad firemným know-how.
V tejto prvej kapitole si veľmi zjednodušene vysvetlíme fungovanie AI nad firemným know-how, ktoré je uložené vo forme textov, či v podkladoch prevoditeľných na texty, ako je napr. zvuk, video, či obrázky. Takéto texty tvoriace firemné know-how sú obvykle uložené na mnohých miestach, napr. vo firemnom systéme pre správu dokumentov, na diskoch, v intranete firmy aj na jej internetových stránkach, vo firemných databázach, diskusných fórach, mailoch, CRM či ERP systémoch a pod.
Pokiaľ viete, čo to je LLM, na akom princípe pracuje, ako sa učí, ako odpovedá na prompt, čo to je embedding, ako sa líšia embeddingy pre RAG od embeddingov vo vnútri LLM, či ako s embeddingami pracuje vektorová databáza, môžete zvyšok tejto kapitoly preskočiť a pokračovať v druhej kapitole Metódy implementácie AI a ich vplyv na zabezpečenie dát.
Na koho bude pôsobiť táto prvá kapitola príliš technicky a podrobne, môže ju tiež preskočiť a pokračovať v druhej kapitole. Odtiaľ sa sem prípadne môže vracať ku konkrétnym pojmom, keď mu nejaký použitý termín v druhej kapitole nebude jasný a rád by sa o ňom niečo dozvedel bližšie.
LLM
„Mozgom“ AI pre prácu nad firemným know-how je tzv. LLM, Large Language Model, slovensky Veľký Jazykový Model. Možno si ho predstaviť ako „niekoho“, kto si prečítal „všetky informácie na svete“ (verejne dostupné texty na internete), a na základe toho odpovedá na otázky užívateľov či rieši ich požiadavky vznesené v prirodzenom jazyku. Odpovede LLM sú opäť v prirodzenom jazyku.
Tento „mozog“ nepremýšľa úplne rovnako ako ľudský mozog, na to vieme ešte príliš málo, ako ľudský mozog premýšľa, aby sme to dokázali simulovať počítačovo. LLM je vybudovaný nad architektúrou zvanou počítačová neurónová sieť. Tá je inšpirovaná činnosťou neurónov v mozgu. Počítačová neurónová sieť sa skladá z ohromného množstva počítačovo reprezentovaných neurónov, každý neurón je simulovaný jedným reálnym číslom. Počítačové neuróny sú umiestnené vo vrstvách, každý neurón vo vrstve je prepojený so všetkými neurónmi predchádzajúcej vrstvy tak, že sa do neho prenáša pomocou váh hodnota z každého prepojeného neurónu predchádzajúcej vrstvy. Zvážené hodnoty vstupných neurónov sa agregujú do výsledného čísla, ku ktorému sa pripočíta konštanta (bias), a na výsledok sa aplikuje aktivačná funkcia (napr. ReLU, Sigmoid alebo Tanh), ktorá do systému vnesie nelinearitu. Tak vznikne hodnota (číslo) výstupného neurónu. Znalosti najväčších LLM sú teda reprezentované architektúrou prepojenia neurónov vo vrstvách a hodnotami stoviek miliárd až biliónov váh a biasov (biasov je menej ako váh, na jeden bias je obvykle tisíc aj viac váh), kde hodnoty váh a biasov sa nastavia pri tréningu (učení).
Zjednodušene, naučenej neurónovej sieti vložíte na vstup reprezentovaný vstupnou vrstvou neurónov nejaké čísla, toľko čísel, koľko má vstupná vrstva neurónov. Tieto čísla sa pomocou nastavených váh a biasov postupne prenášajú do neurónov v ďalších vrstvách, až sa objavia ako nejaké iné čísla v neurónoch na výstupnej vrstve siete. Výstup neurónovej siete je opäť toľko čísel, koľko má výstupná vrstva neurónov.
Keď sa neurónová sieť učí, dávajú sa jej na vstup vzorky vstupných čísel, a ukazujú sa jej vždy pre každý takýto vstupný vzorec, aký vzorec výstupných čísel je očakávaný na výstupe. Neurónová sieť si vo fáze učenia upravuje svoje váhy a bias pomocou procesu, ktorý sa nazýva backpropagation tak, aby sa pre zadané vstupné vzorce jej výstupné vzorce čo najviac podobali očakávaným výstupným vzorcom.
LLM nepracuje s číslami, ale s textami, vyššie popísaný princíp je však podobný:
- Vo fáze učenia sa vezmú „všetky dostupné texty z internetu“. Čo samo o sebe je zložitý proces, zahŕňajúci vyfiltrovanie týchto dát, tzv. kuráciu, kde namiesto obyčajného „predhodenia“ všetkého dostupného textu na vstup LLM sa dáta starostlivo filtrujú, aby sa predišlo skresleniu, šíreniu nepravdivých informácií, a úniku citlivých údajov, stráži sa použitie licencovaných informácií. Každý takto očistený súvislý text z internetu, napr. jedna internetová stránka, jeden stiahnutý dokument, sa po častiach posiela na vstup LLM. Ku každej poslanej vstupnej časti textu sa ako výstup LLM ukáže, aké ďalšie slovo je očakávané na výstupe. Nad stiahnutým textom z internetu vlastne popochádzame oknom, ktoré mení šírku od jedného slova až po maximálne podporovaný počet slov na vstupe LLM, čomu sa hovorí veľkosť kontextového okna LLM. Napr. pri texte „Mačka lezie dierou, pes oknom“ sa na vstup LLM pošle v prvom okne „Mačka“ a ukáže sa, že na výstupe je očakávané slovo „lezie“. Potom sa na vstup LLM pošle rozšírené okno „Mačka lezie“ a ukáže sa, že na výstupe očakávame slovo „dierou“, atď., až sa na koniec pošle „Mačka lezie dierou, pes“ a ukáže sa očakávané „oknom“. Keby veľkosť kontextového okna LLM bola len 3 slová, reálne je o mnoho väčšia a obvykle pojme 150 až 300 strán textu, po dosiahnutí 3 slov na vstupe („Mačka lezie dierou“) by sa ako ďalší vstup LLM poslalo posunuté okno „lezie dierou, pes“ a takto by sa s oknom o veľkosti 3 slová prešlo celým vstupným textom. LLM si vo fáze učenia pomocou backpropagation nastaví zo všetkých poslaných textov na vstup až bilióny svojich váh, a tak sa v jeho váhach zafixujú nielen syntaktické pravidlá prirodzeného jazyka, ale aj znalosti ukryté v zaslaných textoch.
- Natrénované LLM potom rieši požiadavky či otázky užívateľov, alebo agentov AI tak, že textovo sformulované požiadavky či otázky, ktoré svojou dĺžkou neprekročia veľkosť kontextového okna LLM, sa predajú na vstup LLM. Takto naformulovaný text predávaný LLM ako vstup sa nazýva prompt. LLM zo vstupného promptu „vypočíta“ vyššie popísaným prechodom všetkými vrstvami neurónov s nastavenými váhami z doby učenia prvé slovo výstupu, ktoré bude v jeho odpovedi. Toto vypočítané slovo LLM pridá na koniec textu vstupného promptu, a takto upravený prompt pošle opäť sám na seba ako vstup. Tak LLM vypočíta druhé slovo svojej odpovede. To by sa mohlo opakovať donekonečna, preto sa LLM dokáže v určitej chvíli „rozhodnúť, že to už stačí“ a ním takto vygenerovanú odpoveď s konečným počtom slov odovzdá pýtajúcemu sa.
Takto veľmi zjednodušene vysvetlená funkcia LLM stačí pre pochopenie 2 z troch základných metód implementácie AI vo firme nad firemným know-how, popisovaných v druhej kapitole. Existuje ešte tretia, najpoužívanejšia metóda implementácie AI, využívajúca technológiu RAG. Kvôli nej si ešte zjednodušene povieme niečo o prevode textov na čísla.
Embeddingy
LLM je neurónová sieť, tá pracuje s číslami, nie s textami. Je dobré rámcovo chápať, ako sa vstupné texty posielané do LLM v prompte prevedú na čísla, a ako sa z číselného výstupu neurónovej siete LLM spätne urobí slovo. Pre technológiu RAG je prevod textov na čísla zásadný aj z iného dôvodu, kvôli vyhľadávaniu podkladov pre odpoveď LLM.
Metóda prevodu textu na čísla je postavená na niečom, čomu sa hovorí embedding. Embedding, do slovenčiny obvykle neprekladaný výraz, je číselné vyjadrenie kontextového významu slova. Každé slovo ide previesť na embedding, 2 slová kontextovo významovo blízke majú aj sebe blízke embeddingy. Takáto číselná reprezentácia významu slova sa nedá vyjadriť jedným číslom, napr. že by stôl mal číslo (embedding) 4 a stolička 6. To sú si síce celkom blízke čísla, pretože aj stôl a stolička sú si niečím významovo blízke, ale pri takomto spôsobe číslovania slov by sme čoskoro skončili, že už nejde vyjadriť významová blízkosť a vzdialenosť rôznych slov bez toho, aby sa to vzájomne číselne nevylučovalo. Embedding preto nie je jedno číslo, ale vektor čísel, býva to niekedy až viac tisícov čísel v jednom embeddingu. V takomto mnoho-číselnom vektorovom priestore je možné matematicky napr. pomocou Kosínovej podobnosti či Euklidovskej vzdialenosti určovať blízkosť/vzdialenosť jednotlivých embeddingov, vlastne bodov v tomto priestore, reprezentujúc kontextový význam jednotlivých slov. Zároveň do takejto vektorovej reprezentácie kontextového významu slova už ide „zakódovať“ význam všetkých slov tak, aby ich blízkosť vychádzala „správne“.
Embeddingy je možné vytvárať nielen zo slov, ale aj z celých textov, embedding takého textu má v sebe zakódovaný význam celého textu.
Niečo naviac
Pre tých, ktorí majú pocit, že tu zjednodušujeme príliš, a že tu chýba vysvetlenie mnohých vecí, zopár stručných poznámok na záver.
- Embeddingy sa v skutočnosti nerobia zo slov, ale z tzv. tokenov. Token môže byť aj len časť slova. LLM si potom dokáže poradiť aj so slovami, ktoré nikdy nevidel, môže lepšie zvládnuť gramatiku zložitejších jazykov ako je napr. čeština, a je možné vytvárať relatívne malé slovníky tokenov, okolo 100 000 tokenov, ktorými je možné pokryť všetky slová prirodzeného jazyka. Tých je samozrejme oveľa viac, napr. v češtine je slov okolo 250 000, a to len v ich základnej podobe, vďaka skloňovaniu, časovaniu, odborným a slangovým výrazom to ide do miliónov. Metódy, ako robiť tokeny sú rôzne, napr. slovo „nejobhospodařovanější“ by sa mohlo rozpadnúť na tokeny „nej“, „ob“, „hospoda“, „řov“, „an“ a „ější“. Ako je vidieť, z týchto tokenov a ďalších im podobných pôjde zložiť mnoho iných českých slov, bez toho, aby tieto slová museli byť v slovníku.
- Embedding z tokenu sa vypočítava pomocou neurónovej siete. LLM v sebe má slovník, technicky je to prvá vrstva jeho neurónovej siete. Ak má tento slovník napr. 100 000 tokenov a embedding obsahuje 16 384 dimenzií (čísel), jedná sa o maticu 100 000 x 16 384 čísel, kde každý riadok reprezentuje embedding konkrétneho tokenu zo slovníka. Na začiatku učenia je táto matica naplnená náhodnými číslami, počas fázy učenia sa spresňujú pomocou backpropagation nielen váhy neurónovej siete LLM, ale aj tieto čísla, reprezentujúce hodnoty tokenov.
- Vstupom do neurónovej siete LLM nie je rad čísel, ako bolo vysvetlené pre všeobecnú neurónovú sieť vyššie, ale matica, kde na každom riadku je embedding jedného tokenu zo vstupného textu. Navyše je tu pridané pozičné kódovanie, aby neurónová sieť mohla pochopiť, že to nie je len „hromada“ slov (tokenov), ale že tie tokeny majú svoje poradie a vzťah k okolitým tokenom.
- Embeddingy nie je možné ľahko prevádzať spätne na slová. Pri LLM sa to zjednodušene robí tak, že na výstupnej vrstve neurónovej siete je toľko neurónov, koľko je slov (tokenov) v slovníku. Hodnota každého takého neurónu sa prepočíta na pravdepodobnosť, s akou sa má slovo zo slovníka reprezentované týmto neurónom objaviť v textovom výstupe LLM. Ako finálne slovo sa zvolí buď slovo s najvyššou pravdepodobnosťou. Pri tejto voľbe sa ale LLM správa trochu ako robot, odpovede sú stabilné, ale málo kreatívne. Alebo sa podľa tzv. „teploty“ a náhodného výberu zavedie do odpovedí neurčitosť, čo môže viesť ku kreatívnejším odpovediam, ale tiež k „bláboleniu“ či nezmyslom (halucináciám) v odpovediach.
- Pre technológiu RAG, ktorá bude vysvetlená v druhej kapitole, sa používajú trochu iné embeddingy. Tieto embeddingy majú obvykle menší rozmer než embeddingy vo vnútri LLM, napr. 1 536 čísel v jednom embeddingu. Je to preto, že sa musia ukladať do vektorovej databázy a potom v nej rýchlo vyhľadávať embeddingy podľa blízkosti. Vektorová databáza je špecializovaný typ databázy pre ukladanie a správu dát vo forme číselných polí, tzv. vektorov. Na rozdiel od tradičných databáz, ktoré hľadajú presnú zhodu (napr. meno alebo ID), vektorová databáza vie vyhľadávať podľa podobnosti významu (blízkosti embeddingov). Embeddingy pre RAG sa vytvárajú obvykle pomocou špecializovanej neurónovej siete. Pre RAG sa vyrábajú embeddingy z ucelených odstavcov textu, nie len z jednotlivých slov (tokenov). Táto špecializovaná neurónová sieť interne vyrobí embeddingy zo všetkých slov (tokenov) v texte, a vo výsledku ich zhlukne (tzv. pooling) do jediného embeddingu, ktorý obsahuje význam celého textu.
Metódy implementácie AI a ich vplyv na zabezpečenie dát
Existuje viac metód, ako implementovať AI spracovávajúcu firemné know-how s pomocou LLM. Tu popíšeme 3 základné spôsoby týchto implementácií.
Metódy sú tu popisované z technického a bezpečnostného pohľadu. Aspoň v úvode je potrebné zmieniť ľudský faktor, ktorý sa nesmie zanedbať pri akejkoľvek implementácii AI. Implementácia AI prináša často zmenu firemných procesov, kultúry, je potrebné prekonať strach zamestnancov z nahradenia, čo je pri implementácii AI často väčšia prekážka než technológia samotná. Je nutné správne aplikovať change management, vysvetliť dôvody zavedenia, spojiť implementáciu so vzdelávacím procesom, pripraviť pilotný projekt, vybrať AI ambasádorov a urobiť rad ďalších súvisiacich vecí. Toto nie je predmetom článku, popis ako pracovať s ľudským faktorom pri implementácii AI by vydal na celý článok podobného rozsahu ako je tento technický článok. V prípade záujmu čitateľov zaradíme článok o ľudskom faktore a odpovedajúcich postupoch pri implementácii AI do Kontis Insights v budúcnosti.
3 základné metódy implementácie AI spracovávajúcej firemné know-how s pomocou LLM:
Využívanie hotových nástrojov AI bez napojenia na firemné know-how
Jedná sa o nástroje ako je ChatGPT, Microsoft Copilot, Google Gemini, Claude, Perplexity AI, a ďalšie obdobné nástroje na báze LLM.
Využívanie hotových nástrojov AI prináša nulové náklady na vývoj, takmer okamžitý štart riešenia či nízke náklady na prevádzku.
Tieto nástroje nie sú samy o sebe prepojené s firemným know-how, použité LLM o firemnom know-how „nevie nič“. Vo fáze učenia sa možno odpovedajúce LLM naučilo niečo o firme zo zdrojov na internete, napr. bol trénovaný aj na firemných internetových stránkach či iných verejných zdrojoch o firme. Tieto načítané vedomosti boli zlúčené vo váhach LLM s miliardami ostatných vedomostí načítaných z internetu, čo nutne vedie ku generalizácii. LLM na základe požiadavky užívateľa v prompte môže tiež dospieť k tomu, že si nejaké informácie o firme na internete vyhľadá dodatočne a pridá si ich ako ďalší vstup do promptu. K týmto firemným informáciám sa LLM dokáže dostať pomocou služieb nejakého internetového vyhľadávača, takže texty, ktoré dokáže dohľadať, sú podobné ako texty na vstupe v dobe učenia, len napr. aktuálnejšie. Z interného firemného know-how v nich veľa nebude.
Takto používané LLM môže skvelo pomôcť pri riešení pracovných úloh, ku ktorým zamestnanci nepotrebujú firemné know-how. Pred používaním je dobré preškoliť zamestnancov, aby rámcovo chápali, ako LLM funguje a ako správne zostavovať prompt pre LLM, aby dostali čo najlepšie odpovede. Viď prvá kapitola vysvetľujúca funkciu LLM, pokiaľ užívateľ nezadá dostatočne obsiahly prompt dobre vysvetľujúci požiadavku, LLM nemôže poskytnúť kvalitnú odpoveď.
Problém nastáva, ak chce zamestnanec riešiť v AI otázky či požiadavky súvisiace s firemným know-how. LLM nemá odpoveď „zakódovanú“ vo svojich váhach, pretože nebol učený nad firemným know-how. Pravdepodobne neodpovie, že nevie, skôr si začne vymýšľať, tzv. halucinovať. Ak ste napr. výrobná firma vyrábajúca na výrobných linkách, a spýtate sa takéhoto LLM „Ako sa na linke pre výrobu produktu X upína produkt do mechanizmu linky“, LLM nepovie, že nevie, ale zostaví pomerne vierohodnú odpoveď na základe toho, čo sa naučil vo fáze učenia z internetu o rôznych výrobných linkách či upínaní výrobkov. Konkrétne pre vašu firmu a vaše postupy môže odpovedať síce vierohodne, ale úplne nesprávne.
To vedie zamestnancov k vkladaniu dokumentov s firemným know-how do promptu LLM, na základe ktorých má LLM odpovedať. Napr. v uvedenom príklade výrobnej firmy užívateľ do promptu vloží otázku a firemný dokument s pracovnými inštrukciami pre danú výrobnú linku, LLM inštruuje, aby odpovedal len na základe informácií v priloženom dokumente. Obdobne napr. manažér priloží do promptu zmluvu so zákazníkom a spýta sa, či niečo neporušuje konkrétne ním popísanou činnosťou v prompte a pokiaľ áno, aké z toho plynú sankcie.
Problémy s využívaním LLM bez napojenia na firemné know-how
Pokiaľ v takejto implementácii chcú užívatelia riešiť otázky či požiadavky súvisiace s firemným know-how:
- Užívateľ musí vedieť nájsť dokumenty so súvisiacim firemným know-how, ktoré priloží do promptu. Nájsť všetky také dokumenty a ďalšie zdroje informácií, ktoré môžu byť v e-mailoch, chatoch, bug-listoch, firemnom ERP a podobne, nie je ľahké. Užívateľ často nenájde všetko z firemného know-how s otázkou súvisiace.
- Aj keď užívateľ nájde všetky potrebné podklady pre kvalitnú odpoveď LLM, nemusia sa tieto podklady do promptu zmestiť, viď veľkosť kontextového okna LLM vysvetlená v prvej kapitole.
- Aj keď sa podklady do kontextového okna zmestia, pokiaľ sú veľké, LLM v nich horšie hľadá relevantné časti pre odpoveď a stráca detail z dlhého textu.
Zabezpečenie dát tejto metódy
Pri vyššie popísanom vkladaní podkladov k promptu putujú mimo firmu celé firemné dokumenty. Aj keď je komunikácia s LLM po ceste zabezpečená a dodávateľ LLM zaručuje, že nebude na základe týchto dát učiť svoje LLM, či ich využívať na čokoľvek iné ako vygenerovanie odpovede LLM, v mnohých firmách toto v oddeleniach zodpovedajúcich za zabezpečenie firemných dát schválené nebude. Najmä ak putujú promptom von napr. zmluvy so zákazníkmi, viď predchádzajúci príklad, či dokumenty obsahujúce citlivé dáta z pohľadu GDPR, môže to byť problematické. Aspoň sa tu musia prijať ďalšie opatrenia pre zabezpečenie dát, ako napr.
- Preškolenie užívateľov, aké dokumenty môžu vkladať do promptu. S tým je obvykle spojené zavedenie systému klasifikácie firemných dokumentov a priradenie konkrétnej klasifikácie ku každému dokumentu, aby boli užívatelia schopní rozpoznať. Ktoré dokumenty a za akých podmienok môžu do promptu vkladať.
- Zavedenie systémov DLP (Data Loss Prevention), kontrolujúcich odosielané dáta z firmy.
- Implementovanie AI Gateway, ktorá filtruje prompty, anonymizuje dáta, audituje použitie.
Takéto opatrenia nesú ďalšie náklady, a 100% zabezpečenie úniku firemného know-how mimo firmu zaručiť nedokážu. Pokiaľ je toto cieľom, je potrebné LLM „uzavrieť“ v intranete firmy, viď ďalšie 2 metódy. Vlastné všeobecne naučené LLM je možné aj v prípade tejto metódy uzavrieť vo vnútri firmy, avšak nedáva to ekonomicky ani funkčne veľký zmysel bez súčasnej implementácie RAG architektúry. Aké vlastné všeobecne naučené LLM je možné uzatvárať vo vnútri firmy a s akými je to spojené požiadavkami je preto bližšie popísané až v odstavci Zabezpečenie dát mimo firmy pri metóde RAG architektúra.
Tréning a implementácia interného LLM
Na opačnom spektre nákladovosti, doby zavedenia, ale aj zabezpečenia proti úniku firemných dát mimo firmu je metóda vyžadujúca natrénovanie vlastného modelu LLM nad firemným know-how. Takéto LLM potom môže pracovať úplne uzavreté vo firemnom intranete.
Existujú 2 spôsoby tréningu LLM nad firemným know-how:
Full training
Pri Full training sa začína od nuly, LLM nepozná ani jedno slovo, nie sú nastavené jeho váhy. Je potrebné v tréningu použiť „celý internet“, nad ktorého dátami bola vykonaná v prvej kapitole popísaná kurácia a naviac do vstupných tréningových dát zaradiť firemné dáta, opäť očistené. Z popisu tréningu LLM v prvej kapitole je zrejmé, že s tým je spojená vysoká náročnosť na technických odborníkov, zložité vyčistenie dát, veľmi vysoké náklady na počítačový výkon, pre predstavu Full training obvykle vyžaduje tisíce GPU hodín, a fáza tréningu trvá dlho. Na celý proces tréningu je potrebné vyhradiť obvykle niekoľko mesiacov. Z týchto dôvodov je Full training vlastného LLM pre 99 % firiem ekonomicky nezmyselný a nedosiahnuteľný. Zásadný problém pri tréningu na firemné dáta je v tom, že firemné know-how nie je statická vec, naopak sa v čase veľmi rýchlo mení. Každá taká zmena firemných dát by vyžadovala nové pretrénovanie LLM, či jeho dotrénovanie metódou Fine tuning.
Fine tuning
Pri Fine tuning sa začína s už nastaveným, tzn. so všeobecne natrénovaným verejne dostupným LLM ako je napr. Llama či Mistral. Všeobecne natrénované LLM sa potom dotrénuje na firemných dátach. To je ekonomicky aj časovo prijateľnejšie než Full training, ale aj s touto metódou je spojená dlhšia doba implementácie, náročnosť na technických odborníkov a vyčistenie vstupných firemných dát, či nutnosť neustáleho dotrénovávania LLM súvisiaceho so zmenou firemného know-how.
Problémy s tréningom LLM nad firemným know-how
Full training aj Fine tuning so sebou pri tréningu nad firemným know-how nesú kritické nevýhody, medzi ktoré napr. patrí:
- LLM nedokáže v odpovediach uvádzať firemné dokumenty, na základe ktorých vygeneroval odpoveď. Nejde si teda overiť správnosť odpovede LLM, čo vzhľadom k možnému halucinovaniu LLM popísanom vyššie je vážny problém.
- Pri dotrénovaní hrozí riziko, že pri úprave váh LLM zabudne niektoré už naučené veci, to sa nazýva „katastrofické zabúdanie“. Pokiaľ LLM dotrénovávame len na firemných dátach, aj keď pri každom takomto dotrénovaní vždy použijeme celú množinu aktuálnych firemných dát, hrozí, že LLM „zabudne“ niečo z úvodného Full tréningu nad celým internetom, LLM sa stane expertom na firemné know-how, ale prestane zvládať všeobecné otázky alebo logické uvažovanie. Sú rôzne metódy ako toto korigovať, avšak pomerne komplikované a náročné.
- Pri dotrénovaní sú obvykle firemné dáta v porovnaní s dátami z Full tréningu veľmi „malé“, hrozí že LLM sa trénovacie príklady naučí "naspamäť". Výsledkom je, že LLM skvelo odpovedá na dáta z trénovacej sady, ale zlyháva v reálnej prevádzke pri mierne odlišných otázkach.
Zabezpečenie dát tejto metódy
Z hľadiska zabezpečenia firemného know-how, pokiaľ je natrénované LLM uzavreté vo vnútri firmy v jej intranete, je plne zabezpečené, že firemné know-how sa nedostáva mimo firmu.
Avšak počas tréningu LLM nad firemnými dátami sa firemné know-how stalo súčasťou vnútorných váh LLM, viď prvá kapitola o fungovaní LLM. Takto natrénované LLM v odpovediach nedokáže rozlíšiť, ktorý užívateľ mal aké práva na konkrétne firemné dáta, na základe ktorých LLM odpovie. Pokiaľ model pozná odpoveď, odpovie každému, kto sa správne opýta. Tým sa metóda trénovania vlastného LLM stáva pre väčšinu firiem nepoužiteľná, zvonku je firemné know-how zabezpečené dokonale, ale vo vnútri firmy nijako, akýkoľvek zamestnanec s prístupom k promptu LLM sa automaticky dostane k akýmkoľvek informáciám z celého firemného know-how.
Viď vyššie uvedený príklad manažéra, ktorý sa pýta na niečo ku konkrétnej zmluve, naučené LLM nad firemným know-how manažérovi pravdepodobne odpovie správne. Ale pokiaľ sa na niečo o tejto zmluve a zákazníkovi spýta akýkoľvek iný zamestnanec s prístupom k promptu LLM, aj jemu LLM podá všetky informácie, ktoré pozná, bez toho aby tento zamestnanec mal právo do zmlúv firmy so zákazníkmi vidieť.
RAG architektúra
Implementácia AI nad firemnými dátami, založená na RAG architektúre, je v súčasnosti najpoužívanejšia metóda, ako AI na báze LLM naučiť pracovať s firemným know-how.
Pri vyššie popísaných metódach implementácií AI sú stručne načrtnuté problémy, ktoré sú s nimi spojené. Využitie RAG architektúry takmer všetky tieto problémy rieši.
Pod skratkou RAG sa skrýva:
- Retrieval, tzn. vyhľadanie informácií, na základe ktorých má LLM odpovedať na otázku či požiadavku v prompte.
- Augmentation, čiže rozšírenie, vyhľadané informácie sa pripoja do promptu s užívateľskou otázkou/požiadavkou vrátane inštrukcií, ako má LLM odpovedať len na základe týchto pripojených informácií.
- Generation, tzn. generovanie, to už je klasické LLM generovanie odpovede na základe promptu, rozšíreného o súvisiace informácie z firemného know-how.
Vyhľadávanie v know-how firmy
Podstatné u RAG je to Retrieval, vyhľadanie informácií vo firemnom know-how. V RAG architektúre je toto hľadanie založené na embeddingoch, ktorých podstata je vysvetlená v prvej kapitole v sekcii Embeddingy.
Príprava embeddingov
Najprv sa zo všetkých textov predstavujúcich firemné know-how narežú menšie časti textu, tzv. chunky. Cieľom je rozdeliť firemné textové know-how na také časti, ktoré pôjde čo najlepšie poskladať ako kontext otázky užívateľa v prompte LLM. Pokiaľ by bol chunk príliš malý, napr. jedno slovo, nebol by v ňom dostatočne obsiahnutý význam. Pokiaľ by bol chunk príliš veľký, napr. celá kapitola, bol by príliš rozsiahly, s viacerými témami, zle by sa vyhľadával podľa významu a LLM by ho menej efektívne spracovávalo. Sú rôzne metódy, ako text rozdeliť na chunky, napr.:
- prosté rozdelenie na časti textov s fixnou dĺžkou znakov
- pokročilejšie delenie podľa odstavcov či podkapitol
- sofistikované metódy, kde sa konce a začiatky tém v texte určujú opäť pomocou AI
- niekedy sa z chunkov robí hierarchická štruktúra, do LLM sa posiela širšie okolie chunku a pod.
Obvykle sa dĺžka jedného chunku pohybuje okolo 256 až 512 tokenov, ktoré opäť vysvetľujeme v prvej kapitole. Používajú sa rôzne vylepšenia ako je mierne prekrytie textu, každý chunk obsahuje na začiatku 10-20% konca predchádzajúceho chunku, aby sa nestratila súvislosť. Alebo na začiatok každého chunku sa priraďuje kontext celého dokumentu z ktorého pochádza, niečo ako napr. „Tento odstavec pochádza z pracovných inštrukcií pre výrobnú linku X“ či „Tento odstavec pochádza zo zmluvy o X so zákazníkom Y“.
Z takto vytvorených chunkov sa vypočítajú embeddingy pre RAG, popísané v prvej kapitole. Tieto embeddingy sa uložia do vektorovej databázy vrátane originálnych textov, z ktorých vznikli.
Vyhľadanie kontextu k promptu užívateľa
Užívateľ zadá v prompte svoju požiadavku/otázku. Z nej sa buď urobí embedding, alebo sa pred tým zadaný prompt ešte spracuje. Od jednoduchých metód, ako je vyčistenie promptu od zbytočných slov, či generovanie embeddingu z každého slova, až po sofistikované metódy s využitím AI, ako je generovanie variantov formulácií otázky, extrakcia tém z promptu užívateľa, či generovanie fiktívnych odpovedí, z ktorých sa až vytvárajú embeddingy.
Ako výsledok spracovania promptu je jeden či niekoľko embeddingov zo zadaného promptu užívateľa. K tomuto výslednému jednému či niekoľkým embeddingom sa vo vektorovej databáze s uloženými embeddingami z fázy prípravy vyhľadajú im najbližšie embeddingy vo vektorovom priestore. Tie pravdepodobne obsahujú informácie z firemného know-how, súvisiace s otázkou či požiadavkou užívateľa. Pri týchto vyhľadaných embeddingoch sú vo vektorovej databáze uložené aj originálne texty, z ktorých vznikli. Tieto originálne texty sa pridajú do promptu ako kontext požiadavky s inštrukciami, že LLM má odpovedať len na ich základe.
RAG architektúra teda urobí niečo podobné, ako keď užívateľ pri Využívaní hotových nástrojov AI bez napojenia na firemné know-how do promptu pripojí firemné dokumenty, podľa ktorých má LLM odpovedať. RAG to urobí sofistikovanejšie a efektívnejšie. Keď vezmeme vyššie vypísané Problémy s využívaním LLM bez napojenia na firemné know-how, tu v rovnakom poradí platí:
- Na rozdiel od užívateľa pravdepodobne RAG nájde oveľa viac sémanticky (významovo) blízkych informácií z firemného know-how, ktoré súvisia s otázkou užívateľa v prompte. LLM má teda v prompte viac súvisiacich informácií, na základe ktorých môže vygenerovať odpoveď.
- Vyhľadanými podkladmi RAG nie sú celé firemné dokumenty, ale len ich s otázkou súvisiace fragmenty. Takže sa pravdepodobne všetky tieto texty zmestia do kontextového okna LLM.
- Pretože texty obsahujú len z dokumentov vyrezané informácie skutočne súvisiace s otázkou, LLM z nich môže efektívne vytvoriť odpoveď, bez toho aby sa stratil v detaile dlhého textu z veľkej časti nesúvisiaceho s otázkou, viď funkcia LLM.
Doplnenie odpovedí o odkazy na zdroje
RAG architektúra odstraňuje kritický nedostatok Tréningu a implementácie interného LLM, kde LLM nedokáže v odpovediach uvádzať odkazy na firemné dokumenty, z ktorých čerpal informácie pre odpoveď. K embeddingom uloženým vo vektorovej databáze, je možné ako metadáta pripájať odkazy na zdrojové dokumenty, či dokonca ich konkrétne časti, z ktorých bol vo fáze prípravy embedding vyrobený. RAG dokáže tieto odkazy pripájať k odpovediam LLM, pýtajúci sa si môže overiť v originálnom zdroji odpovede, či LLM nehalucinuje.
Zabezpečenie firemného know-how u RAG architektúry bude prebrané v samostatnej podkapitole, RAG dokáže odstrániť takmer všetky nevýhody v zabezpečení dát, menované pri predchádzajúcich dvoch metódach implementácie AI.
Ak použijeme skôr uvedený príklad, kde užívateľ do svojho promptu „Ako sa na linke pre výrobu produktu X upína produkt do mechanizmu linky“ vloží firemný dokument s pracovnými inštrukciami pre danú výrobnú linku, RAG architektúra toto urobí za užívateľa sofistikovanejšie. Popis „upínania“ býva v dokumentácii často rozprestretý medzi textové návody viacerých pracovných inštrukcií, technické výkresy s popiskami, kusovníky, môžu s ním súvisieť aj informácie v dokumentoch o bezpečnosti práce a pod. RAG pri správne položenej otázke vyhľadá pravdepodobne väčšinu týchto textov, očistených o informácie s otázkou nesúvisiace. Odpoveď LLM na prompt obohatený o tieto texty bude presnejšia a výstižnejšia. Vďaka od RAG pripojených odkazov k odpovedi LLM na zdrojové texty môže pýtajúci sa odpoveď overiť v odkazovaných dokumentoch.
Podobne, keď sa manažér v prompte spýta, či pri konkrétnom zákazníkovi niečo neporušuje ním popísanú činnosť, a pokiaľ áno, aké z toho plynú sankcie, na rozdiel od pýtajúceho sa, ktorý k promptu priložil celú zmluvu, RAG vyhľadá nielen túto zmluvu so zákazníkom a v nej len pasáže súvisiace s otázkou, ale obdobné texty RAG možno nájde, pokiaľ existujú, napr. v prílohách zmluvy, v uloženej komunikácii so zákazníkom o predmete zmluvy, v smerniciach špecifikujúcich všeobecné pravidlá firmy pre prácu so zákazníkmi a pod. Odpoveď LLM na otázku bude opäť výrazne lepšia než len s priloženou zmluvou k promptu, s možnosťou overenia v dotknutých dokumentoch, že to tak skutočne je.
Zabezpečenie dát tejto metódy
Vo vnútri firmy
Pri výrobe embeddingov z narezaných textov know-how, popísanej vo fáze ich prípravy, je možné k embeddingom ukladať rôzne metadáta, napr. už zmienené odkazy na zdrojové texty. Tieto metadáta je možné využívať aj na uloženie a následné určenie práv pýtajúceho sa na konkrétne texty, súvisiace s vyrobeným embeddingom. Existuje viac metód, ako to robiť, napr.:
- Filtrovanie podľa metadát. Do metadát embeddingu sa uložia informácie, podľa ktorých budú vo vektorovej databáze pri hľadaní blízkych embeddingov k otázke užívateľa filtrované len embeddingy, na ktoré má užívateľ právo. Takéto filtrovanie enginom vektorovej databázy umožňuje efektívne a rýchle vyhľadanie blízkych embeddingov k embeddingu otázky. Avšak neumožňuje komplexné riadenie práv. K embeddingu sa ako metadáta ukladá napr. zoznam povolených užívateľov, skupina či rola, kam musí užívateľ patriť, a pod. Z toho je vidieť, že takto sa nedá vybudovať komplexný, v čase sa vo firme meniaci systém riadenia práv.
- Riadenie prístupov na základe vzťahov. K embeddingu sa uloží id objektu, z ktorého bol embedding vygenerovaný. Pri hľadaní blízkych embeddingov k otázke užívateľa vektorová databáza vráti napr. 50 najbližších výsledkov bez ohľadu na práva. RAG architektúra sa spýta externej služby, poskytujúcej komplexné riadenie práv vo firme, ktoré z týchto 50 konkrétnych objektov má právo pýtajúci sa vidieť. Do promptu LLM sa pridajú len texty z embeddingov, na ktorých zdrojové objekty má užívateľ právo. Pokiaľ je takých embeddingov vo vyhľadaných 50-tich málo, iteračne RAG vyhľadáva vo vektorovej databáze iné embeddingy napr. s výberom inej metriky či prahovej hodnoty, ktoré možno nie sú otázke užívateľa tak „blízke“ ako predchádzajúcich 50 vyhľadaných, ale užívateľ má právo vidieť objekty s textami spojenými.
Týmto spôsobem je možné z hľadiska zabezpečenia dát zaručiť, že na rozdiel od natrénovaného LLM nad firemným know-how, LLM vráti užívateľovi na jeho otázku či požiadavku iba informácie, na ktoré má užívateľ v rámci firemného know-how právo ich vidieť.
Mimo firmu
RAG architektúru je možné v prípade potreby obdobne ako pri zabezpečení natrénovaného LLM nad firemným know-how plne uzavrieť v intranete firmy a tak firemné know-how plne ochrániť pred akýmkoľvek únikom mimo firmu.
Pre tento prípad je potrebné na firemných serveroch popri firemnej platforme, v ktorej je uložené firemné know-how, prevádzkovať tiež:
- Vektorové databázy pre uloženie embeddingov. Tu sú k dispozícii na trhu veľké škálovateľné riešenia s pokročilými funkciami pre vyhľadávanie, napr. vektorové DB Qdrant či Milvus, aj riešenia jednoduchšie na nastavenie a prevádzku, vhodné pre menšie až stredné projekty, ako napr. ChromaDB.
- Model pre výrobu embeddingov. Na trhu sú špičkové modely ako napr. BGE-M3, ktorý je multilingválny a teda vhodný aj pre češtinu, alebo modely od MixedBread.ai, TEI od Hugging Face či Nomic Embedd.
- Vlastné všeobecne naučené LLM. Na trhu sú LLM so špičkovým výkonom ako napríklad Llama 3.1 alebo novšie modely radu Qwen3.5, ktoré však vyžadujú výkonný hardware, viac GPU s vysokou VRAM. Či sú k dispozícii modely menej náročné na hardware ako Mistral Large 2, Ollama či vLLM. Takéto všeobecne naučené LLM je možné v tomto prípade použitia naviac pomocou Fine tuning dotrénovať napr. na firemný štýl komunikácie, čo je pomerne zaujímavé rozšírenie všeobecnej funkcie LLM.
Je potrebné zvážiť náklady takého riešenia, pri špičkových riešeniach pôjde obstaranie HW do miliónov, nezanedbateľné čiastky pôjdu aj na prevádzku, okrem elektriny a chladenia to budú najmä náklady na expertov, ktorí budú menované systémy udržiavať a aktualizovať. Náklady na expertov sú často vyššie ako samotný hardware a jeho prevádzka.
Z toho dôvodu k uzavretiu vektorovej databázy, modelu pre výrobu embeddingov a LLM, do intranetu firmy sa teda obvykle pristupuje iba v prípadoch, kedy ochrana súkromia je absolútne kritickou požiadavkou, či sa počíta s masívnou prevádzkou AI, kde budú objemy nad 10 miliárd tokenov mesačne, v tomto prípade to niekedy dáva aj ekonomický zmysel.
Väčšina firiem si vystačí s prevádzkou, kde k vektorovej DB, modelu pre výrobu embeddingov a LLM pristupuje cez API k už hotovým riešeniam SaaS. Na trhu sú vysoko kvalitné riešenia od OpenAI, Azure OpenAI Service, Anthropic, DeepSeek (tu bude z hľadiska zabezpečenia v niektorých regiónoch, napr. v EÚ problém, že servery sú v Číne), Groq či Mistral AI.
Existujú univerzálne adaptéry, ako napr. LiteLLM, pomocou ktorých sa dá prepínať medzi jednotlivými riešeniami a prípadne meniť SaaS dodávateľa podľa meniacich sa požiadaviek na zabezpečenie, výkon a kvalitu, bez toho, aby firma musela meniť celý firemný systém.
Dodávatelia SaaS riešení obvykle zaručujú, že na posielaných dátach cez API nebudú trénovať svoje LLM ani ich akokoľvek inak využívať, niektorí dodávatelia zaručujú prevádzku v dátových centrách v EÚ, napr. Azure OpenAI Service či Mistral AI.
Náklady SaaS riešení sa obvykle počítajú z množstva tokenov, ktoré prejdú cez API. Pokiaľ nebude firma posielať cez API miliardy tokenov mesačne, vyjde SaaS riešenie omnoho ekonomickejšie ako prevádzkovať všetko na svojich serveroch.
Jednoduchá porovnávacia tabuľka metód implementácie
| Kritérium | Bez integrácie s know-how | Tréning interného LLM | RAG architektúra |
|---|---|---|---|
| Náklady | nízke | vysoké | stredné |
| Bezpečnosť | nízka | vysoká | vysoká |
| Presnosť | nízka | stredná | vysoká |
Ukážka implementácie AI s RAG v platforme iTutor
Implementácia RAG AI nad firemným know-how v iTutor
iTutor je platforma, ktorá okrem iného:
- zhromažďuje a organizuje firemné know-how
- riadi, ktoré časti know-how sú prístupné ktorým zamestnancom s využitím kompetenčných či kvalifikačných matíc, máp vzdelávania a komplexného systému riadenia práv
- poskytuje zamestnancom informácie, vzdelávanie a podporu pre efektívne používanie nimi zdieľaného firemného know-how vo svojej každodennej práci
- umožňuje overovať pomocou automatického testovania, 360-spätnej väzby, merania plnenia cieľov a ďalších techník, že firemné know-how je správne uložené, odovzdávané a účinne pomáha v pracovnom procese každému zamestnancovi.
Platforma iTutor toho vie oveľa viac, viď popis platformy iTutor, z hľadiska v článku diskutovanej implementácie AI nad firemným know-how takto stručný popis iTutor stačí.
Firemné know-how je v iTutor:
- centralizované vo výkonnom systéme pre správu dokumentov (DMS) iTutor Documents, vo forme textových, obrazových, audio a video dokumentov. iTutor Documents je unikátny pre správu firemného know-how pre všetky typy firiem od malých firiem až po nadnárodné koncerny s multi-jazyčným prostredím, pretože:
- má pokročilé work-flow schvaľovania a pripomienkovania vznikajúcich verzií dokumentov s komplexnou správou prístupových práv k verziám dokumentov
- umožňuje vytvárať jazykové sub-verzie dokumentov s vlastným schvaľovacím work-flow pre prekladateľov a schvaľovateľov jazykových mutácií, podporuje obsahové odchýlky a varianty verzií dokumentov, odpovedajúce konkrétnemu národnému prostrediu, zvykom a legislatíve
- má vstavané business-pluginy pre špecifické spôsoby ukladania know-how, napr. editor pracovných inštrukcií, v ktorom je možné graficky vytvárať modulárne interaktívne pracovné inštrukcie pre prácu zamestnancov na výrobných linkách či v iných pracovných procesoch
- časť firemného know-how je uložená v iTutor LMS/LXP vo forme e-learningových kurzov. To sa týka najmä znalostí a zručností, ktoré je potrebné didakticky na vysokej úrovni odovzdať zamestnancom a on-line si overovať spätnou väzbou pochopenie obsahu. V iTutor je integrovaný nástroj triedy LCMS iTutor Publisher pre vývoj pokročilých e-kurzov a následné spracovanie ich obsahu pre AI. Obsah e-kurzov je obvykle „zabalený“ v rôznych interaktívnych výukových stratégiách a nie je ľahko prístupný pre AI. Text know-how je v e-kurzoch „ukrytý“ v rôznych JS funkcionalitách, simuláciách a interaktívnych prvkoch, k takémuto obsahu sa dá dostať len sofistikovanou interakciou študenta s e-kurzom. iTutor Publisher dokáže z takýchto interaktívnych multimediálnych e-kurzov vytvárať ich textové obrazy, s prevedením aj skrytého obsahu do textovo zrozumiteľnej formy pre AI.
Koho bližšie zaujíma, ako sa v integrovaných systémoch DMS/LMS/LCMS/LXP spravuje firemné know-how, môže si prečítať podrobnejší článok tu.
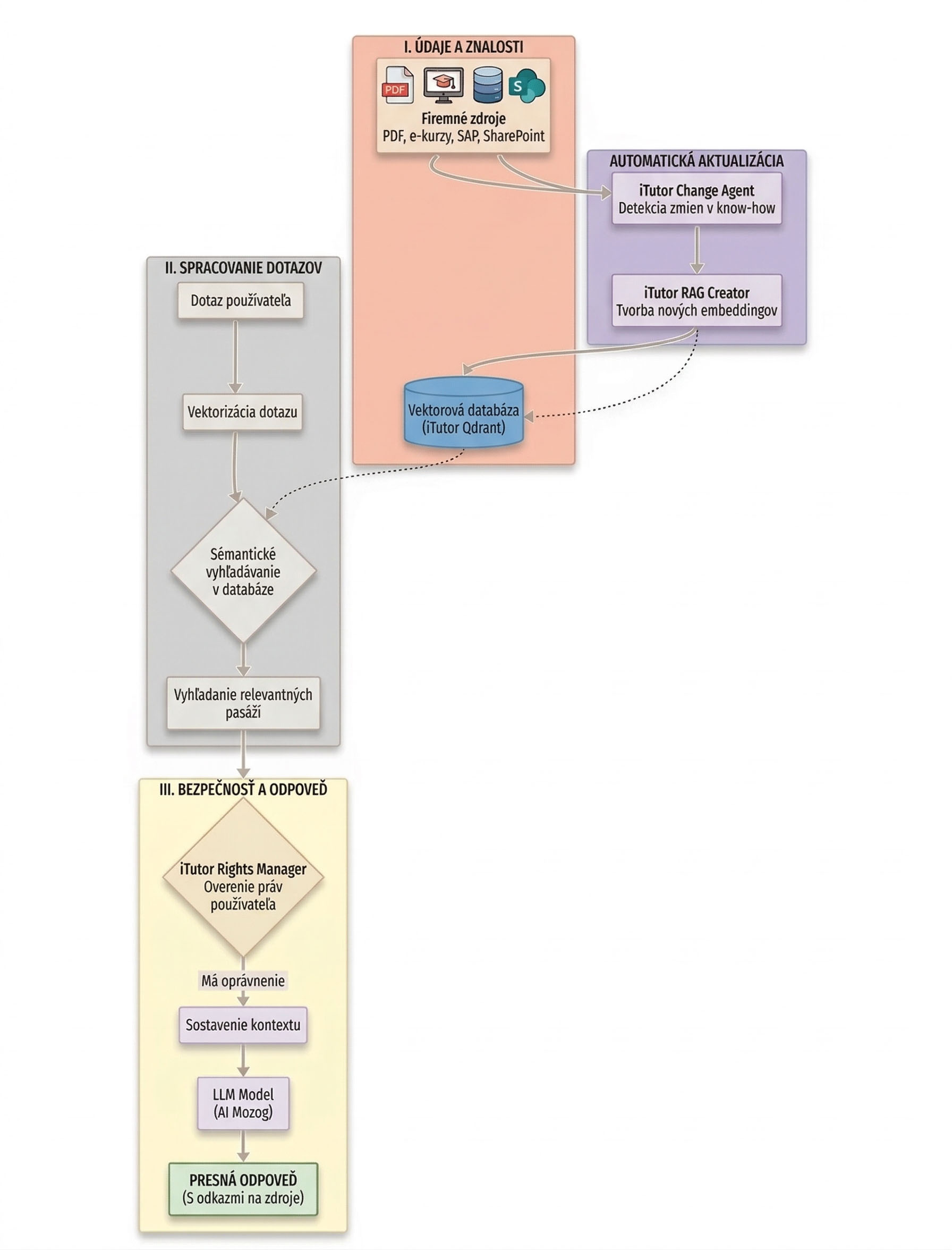
Nad firemným know-how spravovaným v platforme iTutor pracuje modul iTutor AI, ktorý implementuje AI s RAG architektúrou:
- Každý z dokumentov aj e-kurzov v iTutor je možné označiť ako neprístupný pre AI. Tým sa dá zabrániť úniku extrémne citlivých dát napr. z pohľadu GDPR.
- Na pozadí iTutor pracuje iTutor know-how change agent. Ten detekuje všetky zmeny v know-how spravovanom v iTutor. Ak bola vydaná napr. nová verzia dokumentu v iTutor Documents, tento agent zmenu zachytí a odovzdá o nej informáciu ďalšiemu agentovi, iTutor RAG Creatoru.
- iTutor RAG creator je agent tiež bežiaci na pozadí iTutor. Dokáže z každého know-how uloženého v iTutor vytvoriť embeddingy pre RAG s použitím pokročilých metód popísaných v sekcii Príprava. Vytvorené embeddingy ukladá do vektorovej databázy Qdrant, ktorá je súčasťou iTutor. iTutor RAG creator ukladá do vektorovej databázy ku každému embeddingu odkaz na objekt, z ktorého bol vytvorený. To umožňuje komplexne riadiť práva na základe vzťahov, ako je popísané v zabezpečení dát Vo vnútri firmy.
- Obvykle sa firme nepodarí sústrediť všetko svoje know-how v jedinom systéme, tu iTutor. Know-how firmy je často okrem systému s AI funkcionalitou rozprestreté v rade ďalších systémov, ako sú relačné databázy, napr. MS SQL Server, systémy pre správu projektov, napr. Jira, kolaboračné platformy, napr. MS SharePoint, CRM systémy, napr. SalesForce, komunikačné kanály, napr. Slack, systémy zákazníckej podpory, napr. Zendesk, či ERP systémy, napr. SAP.
iTutor RAG creator má vlastný API konektor, pomocou ktorého ho je možné ľahko prepojiť s takmer akýmkoľvek externým systémom, v ktorom je uložená nejaká časť know-how firmy. Tak je možné do RAG vektorovej databázy v iTutor zrkadliť firemné know-how vo forme embeddingov vytvorených iTutor RAG creatorom z ľubovoľného iného firemného zdroja. - Keď užívateľ v iTutor AI zadá požiadavku či otázku, ktorú chce spracovať pomocou AI, spracovanie prebehne podľa princípov podrobne popísaných vyššie v metóde RAG architektúra:
- Z otázky užívateľa iTutor AI vyrobí embedding pomocou extrakcie tém z otázky.
- Vo vektorovej databáze sú vyhľadané embeddingy blízke vyrobenému embeddingu z otázky, nájdené embeddingy obsahujú teda know-how súvisiace s otázkou.
- Na základe aplikácie pokročilého riadenia prístupov na základe vzťahov sú vybrané len tie nájdené embeddingy, na ktoré má pýtajúci sa právo.
- Prompt LLM používaného v iTutor AI je finálne tvorený textom otázky užívateľa, ktorý je obohatený textami vyhľadaných embeddingov obsahujúcich know-how súvisiace s otázkou, a do promptu sú pridané inštrukcie, ako s týmito textami má LLM pracovať. Zjednodušene, že LLM má odpovedať na základe nájdených textov z embeddingov a nie na základe svojich všeobecných znalostí.
- V nastavení iTutor AI je možné určiť, aký model LLM je používaný, či ako sa určuje blízkosť embeddingov vo vektorovej databáze.
- Užívateľ dostane odpoveď od iTutor AI, čo je odpoveď použitého LLM, doplnená technológiou RAG o odkazy na použité dokumenty, e-kurzy v iTutor, alebo objekty z externých systémov, v ktorých si môže overiť správnosť odpovede AI.
- V iTutor AI je implementovaný monitorovací systém, pomocou ktorého môžu administrátori analyzovať odpovede AI a hodnotenie týchto odpovedí od pýtajúcich sa. Na základe toho je možné funkčnosť iTutor AI aj uložené podklady know-how optimalizovať.
- iTutor AI umožňuje svoju funkčnosť „vytiahnuť“ mimo platformu iTutor. Zákazníci si môžu vytvárať na báze iTutor AI svoje vlastné AI chatboty, určovať pre každého takého AI chatbota, na aké dáta firemného know-how má právo a upravovať jeho dizajn. Takýto zákazníkom vytvorený AI chatbot môžu zákazníci umiestňovať do svojho intranetu či na svoje internetové stránky. Na firemných stránkach Kontis si môžete prezrieť jedného takého AI chatbota, vytvoreného v iTutor AI, pracujúceho nad informáciami určenými v iTutor AI pre potenciálnych zákazníkov Kontis.
Platforma iTutor podporuje rad technológií pre single-sign-on, ako je Microsoft Entra ID, AD FS, integrované overenie v AD. Ak má zákazník implementované single-sign-on, môže chatbot vytvorený v iTutor AI umiestnený v intranete zákazníka odpovedať zamestnancovi na základe jeho oprávnení k prístupu ku konkrétnemu know-how firmy. - Existuje aj samostatný produkt iTutor Chatbot odvodený z iTutor AI, v ktorom si môže ktokoľvek ľahko behom pár minút vytvoriť vlastného AI chatbota, metódou drag & drop do neho vhodiť súbory a webové stránky, na základe ktorých chatbot odpovedá. Takého chatbota potom možno prevádzkovať na svojich webových stránkach. iTutor Chatbota si môžete skúsiť urobiť na webe ai.itutor.eu, nielen si tu vyskúšate, ako LLM s RAG architektúrou dokáže odpovedať na vaše otázky na základe sprístupneného know-how, ale prípadne môžete vytvoreného chatbota komerčne používať na svojich stránkach na akýkoľvek účel.
Schématický diagram fungovania RAG v iTutor
Príklady využitia
Na záver sa vrátime k vyššie citovaným príkladom využitia AI u zákazníka:
- Rad výrobných firiem spravuje svoje know-how v iTutor, príklady z automotive si môžete prezrieť tu. Know-how takej firmy býva uložené v iTutor Documents, kde sú spravované napr. dokumenty s výrobnými postupmi, pracovné inštrukcie, smernice, zmluvy. V kurzoch iTutor LMS môžu byť súvisiace informácie obsiahnuté napr. v kurzoch o Bezpečnosti práce. V externých systémoch, ako je napr. SAP, bývajú spravované kusovníky výrobkov s ich popismi, definície výrobných liniek s pracovnými miestami a pod.
Pokiaľ sa užívateľ s takto organizovaným know-how v iTutor AI spýta „Ako sa na linke pre výrobu produktu X upína produkt do mechanizmu linky“, iTutor AI pravdepodobne nájde väčšinu súvisiacich textov zo všetkých menovaných zdrojov, najmä pokiaľ je SAP napojený pomocou iTutor AI API konektora. Odpoveď iTutor AI na prompt bude preto s vysokou pravdepodobnosťou dostatočne presná a výstižná. Vďaka pripojeným odkazom v odpovedi iTutor AI na zdrojové objekty si môže užívateľ odpoveď LLM overiť priamo v odkazovaných objektoch.
- Pokiaľ sa manažér v prompte iTutor AI spýta, či pri konkrétnom zákazníkovi niečo neporušuje ním popísanú činnosť, a pokiaľ áno, aké z toho plynú sankcie, iTutor AI pravdepodobne vyhľadá nielen zmluvu so zákazníkom a v nej pasáže súvisiace s otázkou, ale nájde, pokiaľ existujú, aj súvisiace texty napr. v prílohách zmluvy. To všetko môže byť uložené v iTutor Documents, alebo v nejakom externom systéme napojenom cez iTutor AI API konektor. Ďalej iTutor AI môže vyhľadať komunikáciu so zákazníkom o predmete zmluvy, pokiaľ túto komunikáciu má firma uloženú napr. v MS Exchange a bolo realizované prepojenie Microsoft Graph API s iTutor AI API konektorom. iTutor AI overí, či má pýtajúci sa na nájdené informácie týkajúce sa zmlúv a komunikácie so zákazníkom právo. Pokiaľ áno, dá pýtajúcemu sa pravdepodobne veľmi podrobnú a konkrétnu odpoveď. Pokiaľ pýtajúci sa na takéto informácie právo nemá, pokúsi sa iTutor AI vyhľadať nejaké vzdialenejšie súvisiace informácie s otázkou. Napr. nájde v smerniciach uložených v iTutor Documents všeobecné pravidlá firmy pre prácu a komunikáciu so zákazníkmi. Potom odpovie aspoň podľa týchto informácií. Pýtajúci sa si môže overiť v použitých zdrojoch, ktoré iTutor AI pridá na koniec odpovede, že LLM nehalucinuje.
- Viď vyššie popísaná možnosť vytvárať a „vyťahovať“ AI chatboty mimo platformu iTutor, pokiaľ má zákazník v iTutor implementované single-sign-on, môže si napr. vytvoriť AI chatbota reprezentujúceho pracovníka HR a tohto chatbota umiestniť do intranetu firmy. Tento HR AI chatbot bude schopný odpovedať zamestnancom na ich otázky na HR oddelenie firmy na základe informácií, na ktoré má konkrétny zamestnanec právo plus na základe všetkým zamestnancom prístupného know-how firmy o HR. Ak sa napr. spýta zamestnanec tohto HR AI Chatbota na niečo súvisiace s jeho pracovnou zmluvou, chatbot mu bude pravdepodobne schopný presne odpovedať, pretože tento zamestnanec má oprávnenie na čítanie svojej pracovnej zmluvy, a teda aj HR AI chatbot, ktorého sa zamestnanec pýta, bude mať prístup k informáciám k jeho pracovnej zmluve. Obdobne bude HR AI Chatbot odpovedať jeho manažérovi s prístupom k zmluvám podriadených. Ak sa spýta iný zamestnanec na pracovnú zmluvu kolegu, žiadne konkrétne informácie od HR AI Chatbota nedostane.
Stručne zhrnuté, iTutor je v oblasti AI platforma, ktorá má plne implementovanú RAG architektúru a je schopná spravovať a AI spracovávať všetko firemné know-how. Naviac je schopná spracovať svojím AI know-how uložené v rade ďalších systémov zákazníka. S pomerne nízkymi nákladmi tak možno pomocou platformy iTutor implementovať používanie AI nad všetkým know-how firmy. Riešenie iTutor pre AI spracovanie firemného know-how je možné buď spustiť ihneď, alebo sa iba musia implementovať jednoduché API konektory na ďalšie firemné zdroje, kde je uložené know-how, pokiaľ nie je všetko uložené v iTutor Documents a e-kurzoch v iTutor LMS. Náklady na expertov pri implementácii AI vo firme sú často vyššie než na HW a prevádzku technického riešenia. Hotová platforma iTutor tieto náklady minimalizuje.